Books Online Scraper
Pipeline ETL complet pour collecter, nettoyer et organiser les données de 1000 livres depuis Books to Scrape.
Aperçu du projet
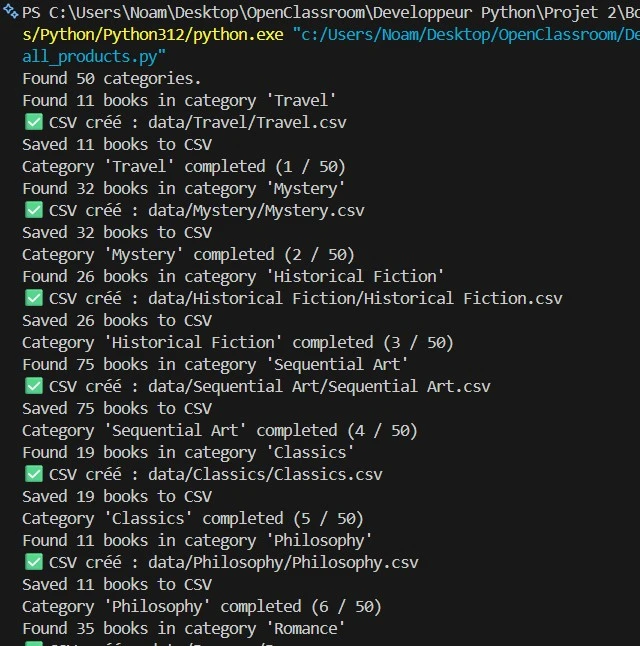
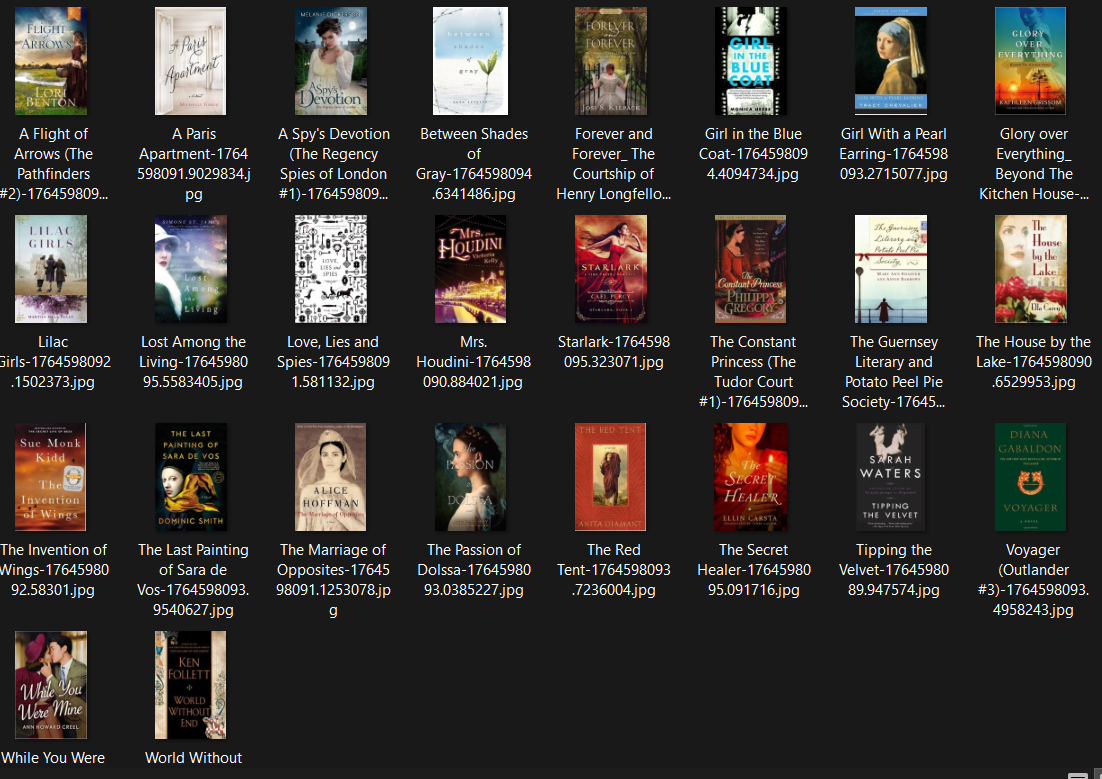
Ce projet met en œuvre un pipeline ETL (Extract, Transform, Load) complet pour collecter des données depuis le site Books to Scrape. L'étape d'extraction parcourt récursivement les catégories et produits, récupérant informations et images sur un millier de livres.
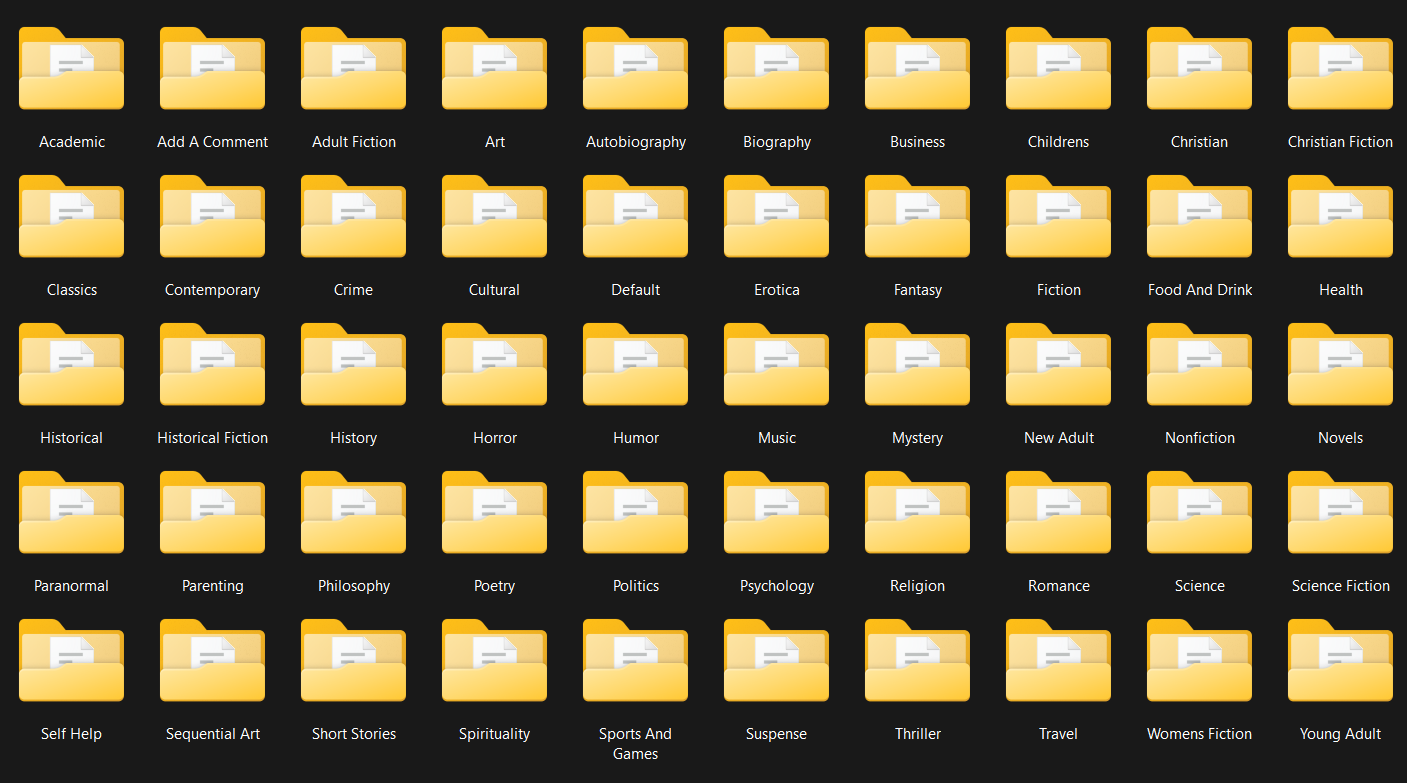
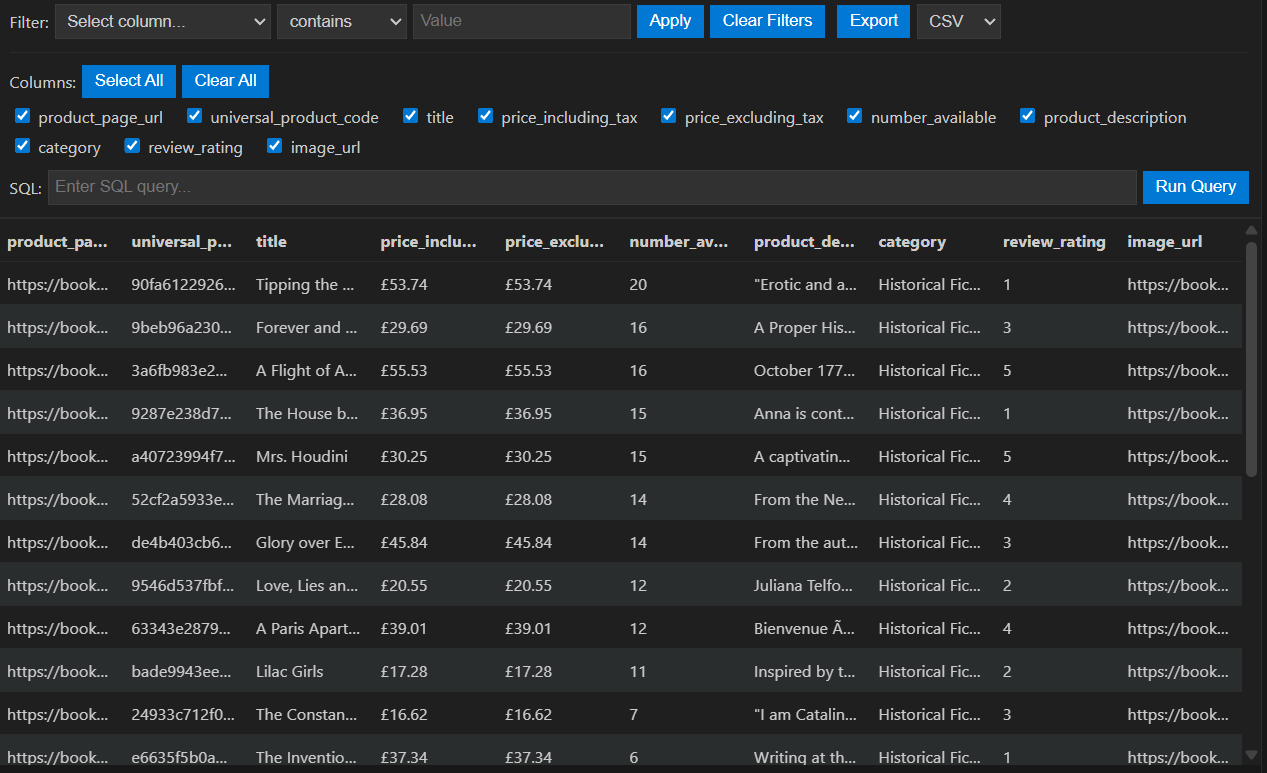
La phase de transformation assure le nettoyage des données (encodage, formatage des prix, gestion des caractères spéciaux), garantissant leur qualité. Enfin, le chargement organise les résultats dans une structure de fichiers CSV et dossiers d'images cohérente.
L'architecture est optimisée pour la performance (via des sessions HTTP réutilisées) et la maintenabilité.
Défis rencontrés
Extraction récursive
Parcours automatisé de 50 catégories et 1000 pages produits avec gestion de la pagination.
Nettoyage des données
Gestion de l'encodage, formatage des prix en float et traitement des caractères spéciaux pour des CSV propres.
Performance réseau
Optimisation via la réutilisation de sessions HTTP pour réduire le temps d'exécution global.
Captures d'écran